
As Page recently wrote, parallax-based layouts were definitely one of the prevailing trends in 2013. As a compelling way to tell a visual story in an editorial context, they provide a powerful and visually engaging approach. Quickly, however, “parallax” turned into a popular framework for constructing entire sites. Building a parallax-based website to be SEO-friendly and reasonably fast requires some unique work-arounds. We’ll take a look at some of them — and we’ll also look at why, in most cases, they’re probably not worth it.
The problem
In addition to the great points that Page makes, there are some technical problems to consider when building a one-page website.
- SEO is perhaps the biggest loser. It suffers because you’ve lost the ability to optimize each page. The entire site is basically being indexed as one, large page (which it is).
- Also lost is the ability to correlate site activity to measurable gains (leads, purchases, etc). Maintaining a codebase that is not naturally split into logical and discrete sections can become unwieldy, quickly.
- Performance is also crippled — all those beautifully large background images and parallax layers are loaded at once, which can be expensive, causing a noticeably slower experience for your users.
In short, by building a site in this manner, you’re relinquishing all the inherent benefits a multi-page site provides. While there are workarounds for all the issues listed above, they are just that — workarounds, which become one more area of complexity that needs to be maintained.
Some workarounds
For instance, all three of these technical challenges can be offset by making the site more dynamic. Specifically, a progressively-enhanced, Ajax-based approach can be used. The basic idea is that the various “pages” (really, the blocks of the long scrolling page) are loaded dynamically via Ajax when needed – either by nav click or page scroll. At the same time, the url is “changed” in such a way that the new “page” has a new, unique URL. From a search engine’s standpoint, the page can be indexed uniquely, gaining all the benefits of targeted H1 and meta-tags. From the user’s perspective, the page scrolls smoothly, from one section to the next, allowing for th fancy parallax-based design that the kids are so into.
How does this work? There are a number of pre-built jQuery libraries that allow for this kind of functionality, and even a WordPress theme that (sort of) works. However you go about it, the basic principles are the same, as illustrated in this simple demo. The demo works in HTML5-compatible browsers only — see my notes below for more details on that.
https://www.newfangled.com/parallax_test/index.php
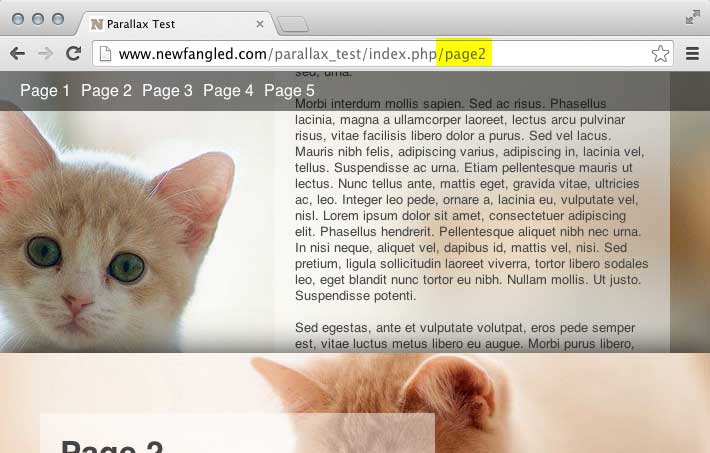
Note that, as you click and scroll around, the URL changes to indicate which “page” you’re looking at. From the search engine’s point of view, these are seen and indexed as separate pages, since we’re using the pushState() method that at least Google and Bing recognize.
It might not be visually apparent, but each section is being loaded dynamically, allowing for a fast initial page load. Using the back button will capture the history of the pages that you’ve viewed. Accessing a page URL directly, however, will take you to the subsection in question.
Finally, since we’re utilizing the standard approach — discrete assets to serve up individual pages — it becomes possible to provide a completly non-single-page (but still navigatable) experience to those users who need it, either from a browser or accessibility standpoint. Try it out: turn off your javascript and reload the page.
A closer look
First, we start with a basic, functional navigation that links to actual pages. Worst-case scenario, if the user doesn’t have JavaScript, they can still click through to these pages. These pages can even be dynamic, so elements like the header and footer display only if the page is not accessed via an Ajax call. Below the links, we’ll add the placeholders that each “page” will be loaded into.
<div id="nav"> <a class="mainnav" rel-container="page1" href="/parallax_test/page1.php"> Page 1 </a> <a class="mainnav" rel-container="page2" href="/parallax_test/page2.php"> Page 2 </a> <a class="mainnav" rel-container="page3" href="/parallax_test/page3.php"> Page 3 </a> <a class="mainnav" rel-container="page4" href="/parallax_test/page4.php"> Page 4 </a> <a class="mainnav" rel-container="page5" href="/parallax_test/page5.php"> Page 5 </a> </div> <div class="container" id="page1" data-speed="20"></div> <div class="container" id="page2" data-speed="2"></div> <div class="container" id="page3" data-speed="10"></div> <div class="container" id="page4" data-speed="5"></div> <div class="container" id="page5" data-speed="9"></div>
Next, we’ll add some JavaScript that loads each block dynamically and ties a listener to the main navigation element that scrolls down to that block.
$('.mainnav').each( function(){
var containerId = $(this).attr( 'rel-container' );
loadContainer( containerId );
$(this).on( "click", function( event ){
event.preventDefault();
scrollToContainer( containerId );
})
})
We’ll then add some JavaScript that detects when a given block gains prominence in the visible window. When it does, we’ll update the browser history using the HTML5 api.
$(window).on('scroll', function () {
var newPage;
$('.container').each(function () {
if (!newPage) {
if ( $(this).offset().top > ($(window).scrollTop()) ) {
newPage = $(this).attr('id');
} else {}
}
})
if ((typeof(newPage) != 'undefined') && newPage != currentPage) {
updateHistory( newPage );
currentPage = newPage;
}
});
function updateHistory( id ){
history.pushState('', 'New URL: '+id, baseUrl + id);
}
Finally, we’ll want to listen for the URL changing, either via the user hitting the forward/back buttons, or the page (re)loading. When this happens, we’ll trigger the appropriate block view.
window.onpopstate = function(event) {
var fullUrl = location.pathname;
urlPart = fullUrl.replace( baseUrl, '' );
if ((typeof(urlPart) != 'undefined')) {
scrollToContainer( urlPart );
}
};
Granted, this is a very basic example.
We’re relying on the HTML5 history API, which means it won’t work on older browsers like IE 8 and 9. This can also be achieved in a more cross-browser way using tools like history.js and htm5-history-api. It’s worth noting that, to my knowledge, these methods all make use of the #! (hash-bang) method, not the pushState() method. Google and Bing have both indicated that the pushState() JavaScript method is the prefered way to indicate that an Ajax load should be indexed/treated as a unique page.
I’m not showing any progressive loading techniques, although all the pieces are in place to do that, based upon scroll activity.
The parallax functionality is also very basic and was adopted from the tutorial here. Check out the source code to see the complete functionality, including the basic parallax code itself.
So?
This should give you the general gist of what we’re doing. As you can see, its adds a bunch of steps and dependencies to what would otherwise be a dirt-simple multi-page structure. While not necessarily brittle, it does contain a good deal of complexity that otherwise wouldn’t be there.
What, then, is the takeaway? In the end, are these workarounds worth it? In my opinion, no. The biggest issue to consider is the underlying purpose being served. An editorial article or any “self-contained” piece of content can benefit from the visual storytelling that parallax provides. On the other hand, if a user is switching between disparate elements quickly (say, the pages of a website), then a parallax approach can make the site awkward at best — and often unusable. Ultimately, when considering a parallax-based site build, I’ve found that the UI issues and technical challenges described above far outway the visual benefits. Which, maybe, weren’t all that great to begin with anyway.